What is Post-mortem (Incident Report)?
Introduction
A postmortem (or postmortem) is a process intended to help you learn from past incidents. It typically involves an analysis or discussion soon after an event has taken place.

Postmortems typically involve blame-free analysis and discussion soon after an incident or event has taken place. An artifact is produced that includes a detailed description of exactly what went wrong in order to cause the incident, along with a list of steps to take in order to prevent a similar incident from occurring again in the future. An analysis of how your incident response process itself worked during the incident should also be included in the discussion. The value of postmortems comes from helping institutionalize a culture of continuous improvement. This way, teams are better prepared when another incident inevitably occurs with mission- or business-critical systems.
As your systems scale and become more complex, failure is inevitable, assessment and remediation is more involved and time-consuming, and it becomes increasingly painful to repeat recurring mistakes. Not having data when you need it is expensive.
Streamlining the postmortem process is key to helping your team get the most from their postmortem time investment: spending less time conducting the postmortem, while extracting more effective learnings, is a faster path to increased operational maturity. In fact, the true value of postmortems comes from helping institutionalize a positive culture around frequent and iterative improvement.
Other names for Postmortem
Organizations may refer to the postmortem process in slightly many different ways e.g.:
-Learning Review
-After-Action Review
-Incident Review
-Incident Report
-Post-Incident Review
-Root Cause Analysis (or RCA)
Things to include in a postmortem:
In general, an effective postmortem report tells a story. Incident postmortem reports should include the following:
-A high-level summary of what happened
-Which services and customers were affected? How long and severe was the issue? Who was involved in the response? How did we ultimately fix the problem?
-A root cause analysis
-What were the origins of failure? Why do we think this happened?
-Steps taken to diagnose, assess, and resolve
-What actions were taken? Which were effective? Which were detrimental?
-A timeline of significant activity
-Centralize key activities from chat conversations, incident details, and more.
-Learnings and next steps
-What went well? What didn't go well? How do we prevent this issue from happening again?
Who is or should be responsible for the Postmortem?
An incident commander should select one responder to own the post-mortem. Though the selected postmortem owner is not solely reponsible for completing the post-mortem themselves. Writing a postmortem is a collaborative effort and should include everyone involved in the incident response. While engineering will lead the analysis, the postmortem process should involve management, customer support, and business communications teams. The postmortem owner coordinates with everyone who needs to be involved to ensure it is completed in a timely manner.
It is important to designate a single owner to avoid the bystander effect. If you ask all responders or a team to do the postmortem, you risk everyone assuming someone else is doing it, therefore no one does.
When to do Postmortem?
Postmortems are done shortly after the incident is resolved, while the context is still fresh for all responders. Just as resolving a major incident becomes top priority when it occurs, completing the postmortem is prioritized over planned work. Completing the postmortem is the final step of your incident response process. Delaying the postmortem delays key learning that will prevent the incident from recurring.
Example of Post-mortem (Incident Report)
Friday, June 28, 2019
By the DevOps Team
Earlier this week we experienced a network outage in our Consolidatedalliance website. This incident report is provided to give details of the nature of the outage and our responses.
The outage occurred on Friday, June 28, 2019. We know this outage and downtime issue has impacted our valued developers and users, and we apologize to everyone who was affected.
Issue Summary
From 6:26 PM to 7:58 PM WAT, requests to most home page of consolidatedalliance.ng resulted in 404 error response messages. Access to other parts of the website was also affected including the login page and booking manager page. The issue affected 80% of traffic to this API infrastructure. Users could continue to access certain parts of the website where you didn't have to go through the home page. The root cause of this outage was an invalid href attribute configuration change in the header file that exposed a bug in the home page. The href attribute specifies the base URL for all relative URLs on a page. It was wrongly set to localhost instead of consolidatedalliance.ng
Timeline (all times West African Time (WAT))
6:19 PM: header file push begins
6:26 PM: Outage begins
6:26 PM: a customer alerted the support team
7:15 PM: Successful header file configuration change rollback
7:19 PM: Server restarts begin
7:58 PM: 100% of traffic back online
Root Cause
At 6:19 PM WAT, an invalid href attribute in the header file was inadvertently released to the production environment without first being tested. The change specified an invalid url for the home page. This made the page to point to localhost instead of consolidatedalliance.ng As a result, the homepage became inaccessible which also blocked access to other parts of the site and the downtime began.
Resolution and recovery
At 6:26 PM WAT, the support team informed the DevOps that a customer called in to complain about the inability to access the login page to his profile. By 6:40 PM, the developers identified the problem and set to work immediately.
At 7:15 PM, we attempted to roll back the problematic configuration change and it was successful since we had previously detected the issue.
At 7:19, We restarted the server. By 7:58, 100% of traffic was recovered and everything went back to normal.
Corrective and Preventative Measures
We've conducted an internal review and analysis of the outage. The following are actions we are taking to address the causes of the issue and to help prevent recurrence and improve response times:
-we will put measures in place to make sure out DevOps get alerted first before the customer discover any bugs in the future.
-we agreed to implement DataDog APIs to alert the team of any issues.
-we put measures in place to always test any little changes to avoid such occurrences.
We appreciate your patience while we reviewed and fixed the issue. Again, we apologize for the inconveniences experienced and the impact to you, your users and your business. We thank you for your business with us.
Sincerely,
The DevOps Team



Advertisement
Advertisement
Advertisement
-
 What happens when you type any URL in your browser and press Enter
What happens when you type any URL in your browser and press Enter -
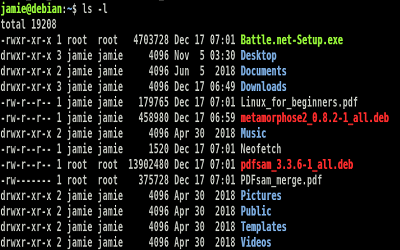 What you get when you type ls *.c and hit Enter in shell
What you get when you type ls *.c and hit Enter in shell -
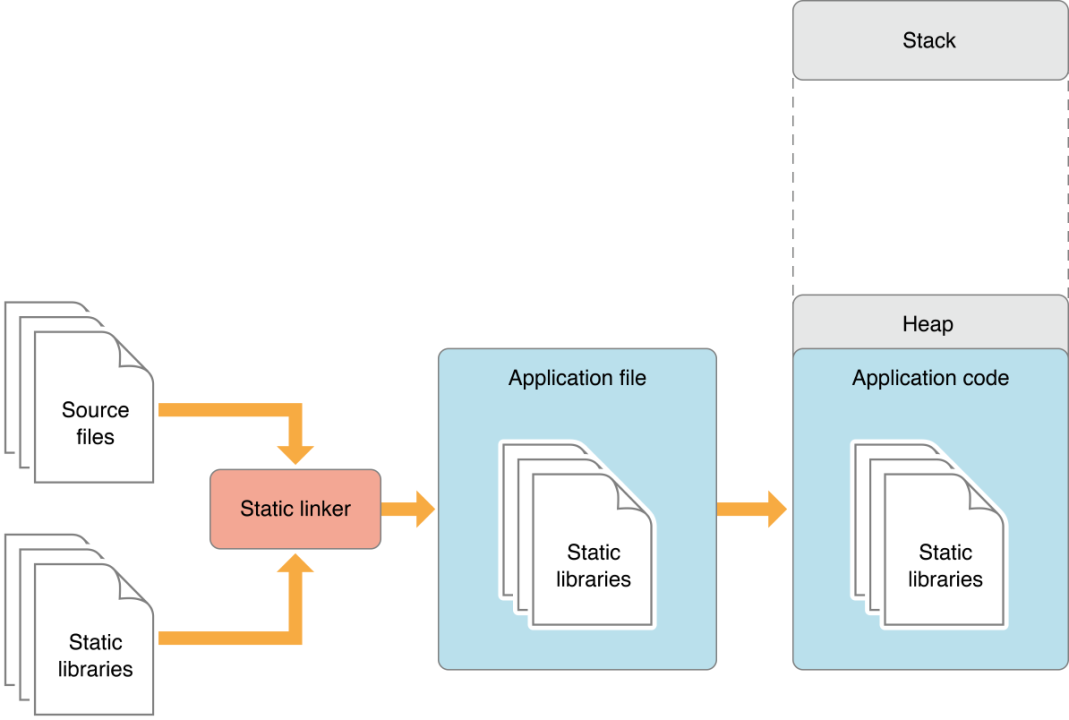 The differences between static and dynamic libraries
The differences between static and dynamic libraries -
 What is IoT?
What is IoT? -
 What is Post-mortem (Incident Report)?
What is Post-mortem (Incident Report)? -
 Machine Learning
Machine Learning -
 The C preprocessor's Worst abuse - (IOCCC winner, 1986)
The C preprocessor's Worst abuse - (IOCCC winner, 1986) -
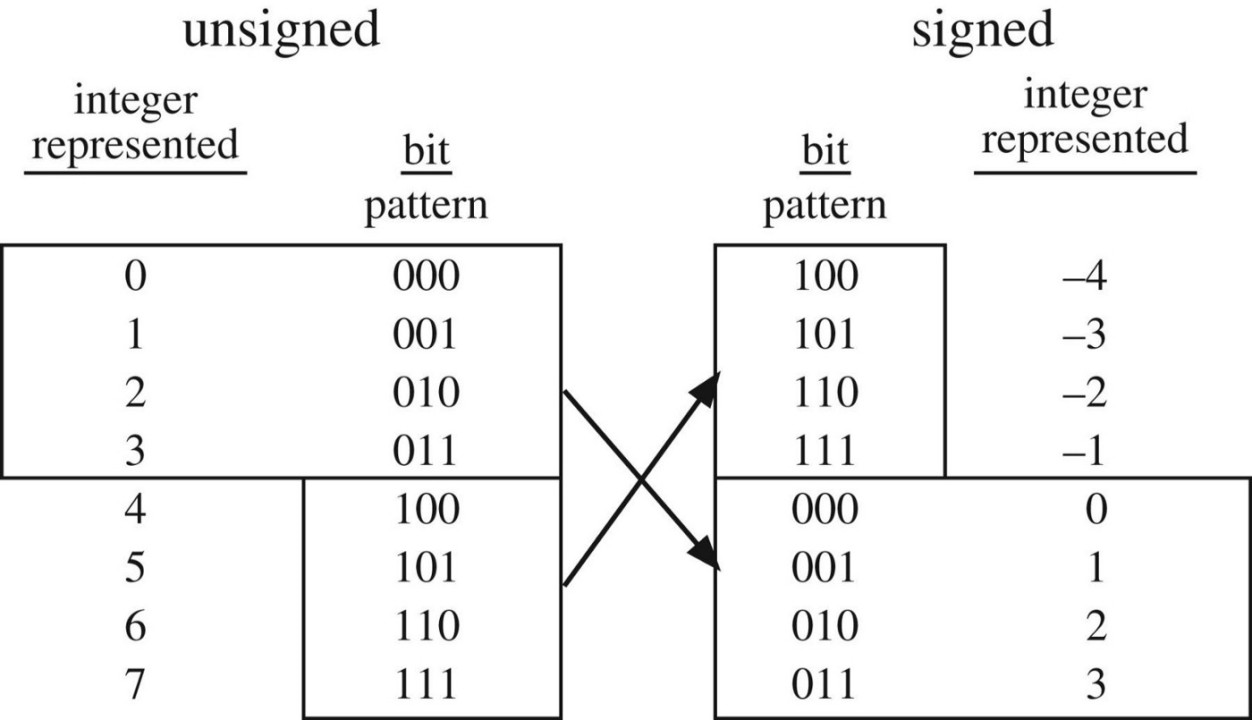 How integers are stored in memory using two's complement in digital computers
How integers are stored in memory using two's complement in digital computers